

ROI or Die.
Why the AI accountability gap is the most expensive problem in tech right now.

In 2024, corporations spent $252 billion on AI. That same year, several studies found that the majority of enterprise AI pilots delivered zero measurable impact on the P&L. Not “underperformed expectations.” Zero. No measurable bottom-line impact whatsoever.
By 2025, 42% of companies had abandoned most of their AI initiatives, up from 17% the year before. The average organization now scraps nearly half its AI proof-of-concepts before they reach production. Gartner predicted that at least 30% of generative AI projects would be abandoned after proof-of-concept by end of 2025. RAND Corporation found that AI projects fail at twice the rate of non-AI IT projects.
Read those numbers again. A quarter-trillion dollars deployed. Ninety-five percent failure rate.
And yet, at the same time, others are making AI work. Decisively.
AI-powered personalization is lifting ecommerce conversion rates by up to 23%. Contact centers using AI see 30% operational cost reductions. A Harvard Business School study found AI users completed tasks 25% faster at 40% higher quality. Early GenAI adopters report $3.70 in value for every dollar invested, with top performers hitting $10.30 per dollar. McKinsey found that the 6% of organizations they classify as “AI high performers” attribute over 5% of their entire EBIT to AI.
Developers using GitHub Copilot code 55% faster in controlled studies. 88% of accepted Copilot suggestions stay in the codebase. Teams across the software development lifecycle report 15%+ velocity gains from AI tooling, and coding has become a $4 billion AI category in 2025, up from $550 million the year before. That’s not a pilot. That’s a market.
Same technology. Same year. Same models. Radically different outcomes.
So what separates the 5% that extract millions in value from the 95% that produce nothing? It’s not the model. It’s talent, it’s data, and…
It’s accountability. And the lack of it has a name.
The Lie
Two words: “strategic investment.”
This is how AI projects avoid accountability. At every altitude. In every organization. And it’s the most expensive phrase in corporate vocabulary right now.
Think about something. If a VP of engineering walked into a budget review and said “I need $3 million for a new microservices architecture, no measurable business outcome expected for 18 months, and I can’t tell you what metric it will move”, that request would be dead before lunch. The CFO would laugh. The board would never see it.
Now replace “microservices architecture” with “AI.” Same request. Same missing numbers. Different outcome. The room nods. The budget gets approved. The CFO might even smile. “We need to be investing in AI.”
This is the exemption. And it operates at every altitude.
In the boardroom, the pattern is remarkably consistent. An investor sits on four boards. Every board meeting, the CEO presents the AI roadmap. She asks about ROI. The CEO says “it’s a strategic investment, we’ll see returns in phase two.” She doesn’t push harder because she doesn’t want to be the partner who “doesn’t get AI.” Multiply this by every firm, every fund, every seat in the portfolio. That’s how billions get deployed without a number attached.
One level down, in the executive suite, the pattern mutates but survives. A VP of Product has four AI initiatives running. One is a zombie with no measurable impact, no clear path to impact, but it has executive sponsorship and “strategic” status. Killing it means a political fight with the exec who championed it. So the zombie lives, quietly consuming budget and engineering time that should be flowing to the projects that are actually working. He’s subsidizing failure with the budget meant for success. He knows it. His team knows it. Nobody says it.
On the product team, a PM is sitting in a review. Someone asks about ROI for the AI feature. The project lead deploys the magic words: “it’s a strategic investment.” Everyone nods. The question dies. The project lives another quarter. The PM notices the pattern over time: projects with numbers get funded aggressively or killed fast. Decisions happen. “Strategic” projects just linger, never killed, never funded properly, never held accountable. They exist in a permanent state of limbo, consuming resources and producing nothing.
Meanwhile, a solo founder with eleven months of runway doesn’t get to play “strategic.” Every dollar spent on AI that doesn’t convert to revenue, retention, or reduced costs is a dollar closer to death. But he’s watching competitors raise $20 million rounds on demos and narrative. AI-native. Foundation model. Platform play. Zero revenue. He’s wondering if he’s doing it wrong. He’s not. He’s the one doing it right. He just doesn’t know it yet.
“Strategic investment” is not a strategy. It’s a hiding place. And its getting crowded.
You Already Know How to Do This
Here’s what makes the AI accountability gap so maddening: it’s not a knowledge problem. Every organization already has the tools to prevent it.
You don’t ship a feature without success criteria. You don’t approve headcount without a business case. You don’t launch a product without knowing what metric it’s supposed to move. You don’t hand an engineering team six months and a blank check and say “surprise me.” You run quarterly business reviews. You set OKRs. You kill projects that miss milestones. You’ve been doing this for decades.
Except with AI. With AI, you do all of the things you’d never do with any other investment. You fund without milestones. You launch without success criteria. You give “strategic” projects unlimited runway. And then you’re shocked that 95% of pilots produce nothing.
IBM spent $5 billion building Watson Health. Five billion. They acquired four health data companies, employed 7,000 people, and partnered with MD Anderson Cancer Center, which spent $62 million over four years on a Watson-powered oncology advisor. The system was never used on a single actual patient. MD Anderson killed the project citing cost overruns, delays, and procurement problems. IBM eventually sold Watson Health to a private equity firm for roughly $1 billion. A $4 billion write-down on a “strategic investment” that nobody held accountable until it was too late.
Zillow trusted its algorithm to buy homes. Their Zestimate model had been valuing homes for years. Good enough for browsing, not good enough for betting the company. But they bet the company anyway. In Q3 2021, Zillow’s iBuying division lost $304 million. Total write-downs exceeded $500 million. They laid off 2,000 people, 25% of their workforce. Their stock lost $9 billion in market cap. Their competitors, Opendoor and Offerpad, used similar models but with tighter risk controls and shorter feedback loops. They survived. Zillow didn’t.
The technology worked in both cases. The accountability didn’t. Normal investment discipline; milestones, kill criteria, measurable outcomes, would have caught the problem long before it became catastrophic. But the rules didn’t apply. Because AI.
Here’s the double standard made concrete. Zillow’s competitors, Opendoor and Offerpad, used similar pricing algorithms in the same markets during the same period. Opendoor reported $170 million in profits and 7.3% gross margins in the same quarter Zillow lost $304 million. The difference wasn’t the model. Opendoor had been in the iBuying business since 2014 and had built tighter risk controls, shorter feedback loops, and a healthy respect for what the algorithm could and couldn’t predict. They treated the algorithm as a tool with known limitations. Zillow treated it as an oracle and scaled aggressively on faith. Same technology, same market, but opposite discipline, opposite outcome.
IBM’s story is even more instructive. Watson Health wasn’t a bad idea. It was a badly managed investment. The MD Anderson project’s original budget was $2.4 million. It ballooned to $62 million over four years. A University of Texas audit found that contracts were deliberately structured just below the threshold for board approval, avoiding the very scrutiny that would have caught the problem. The system was built on a legacy medical records platform that MD Anderson had already replaced. Nobody stopped to ask whether the integration made sense. Nobody set a milestone that would have surfaced the misalignment. The project drifted for years under “strategic” cover until the audit blew it up. If someone had asked “what’s the dollar, and when do we see it?” at month six, the $62 million loss could have been a $5 million lesson.
Now look at the winners. McKinsey’s 2025 AI survey tested 25 organizational attributes to find what predicts bottom-line impact from AI. The single strongest predictor was workflow redesign with clear milestones before scaling. The 6% of organizations seeing real EBIT impact are three times more likely to have redesigned workflows and set measurable targets before they deployed. They didn’t have better technology. They had better questions. They asked “what’s the dollar?” before they wrote a line of code.
BCG’s 2025 research on AI in finance tells the same story from a different angle. The highest-ROI teams don’t just build AI, they focus relentlessly on value from day one. They prioritize quick wins over open-ended learning. They allocate dedicated budgets. They emphasize early impact. BCG found that emphasizing early impact increases the likelihood of AI project success by six percentage points. In a landscape where the baseline success rate is in the single digits, that’s enormous. The pattern is consistent: discipline first, technology second.
The discipline already exists. You just stopped applying it when someone attached the word “AI” to the budget request. Stop making the exception.
The Framework
“ROI or die”. Here’s a reminder to use the framework you already have.
Before any AI initiative gets funded, run it through a test of value. Use the framework you use for everything else. I use PROVE-IT (link here.) If it doesn’t pass, it doesn’t get built. If it does, it enters the cycle.
Explore → Exploit → Platformise.
Explore [20% of AI budget]. Tiny projects. Small segments. Limited exposure. Fast and cheap. The goal isn’t scale, it’s signal. Did we find a dollar worth chasing? Run the experiment in weeks, not months. Most things die here. That’s not failure, that’s the system working. The ROI of Explore is learning speed. The faster you can run cheap experiments and kill the losers, the faster you find the winners. A team running four small experiments a month will outperform a team running one big “strategic” initiative every quarter. Every time.
Exploit [50% of AI budget]. This is where the money is made. The winners from Explore get scaled. Broad rollout. Full integration into existing funnels. Conversion optimization, support deflection, pricing, ops efficiency, workflow acceleration. AI applied to the places you already make or spend money. ROI-positive within 90 days or kill it. No exceptions. No “phase two.” No “strategic.” Show the dollar or free up the budget for something that will. This track funds everything else. If Exploit isn’t performing, you don’t have permission to explore or invest long-term. You have to earn the right to innovate by proving you can execute.
Platformise [30% of AI budget]. The proven wins from Exploit get built into infrastructure. Distilled capabilities. Reusable systems. Self-service tools that make the next cycle of Explore faster and cheaper. This is where data flywheels live, where memory systems compound, where proprietary feedback loops create defensibility. Platformise still has ROI, it’s just measured in compounding velocity rather than quarterly P&L.
The cycle is the point. Explore feeds Exploit. Kill fast. Only the winners graduate. Exploit feeds Platformise. Double down. The proven wins become infrastructure. And Platformise feeds back into Explore. Better platform means faster, cheaper experiments. Each revolution of the flywheel gets faster than the last.
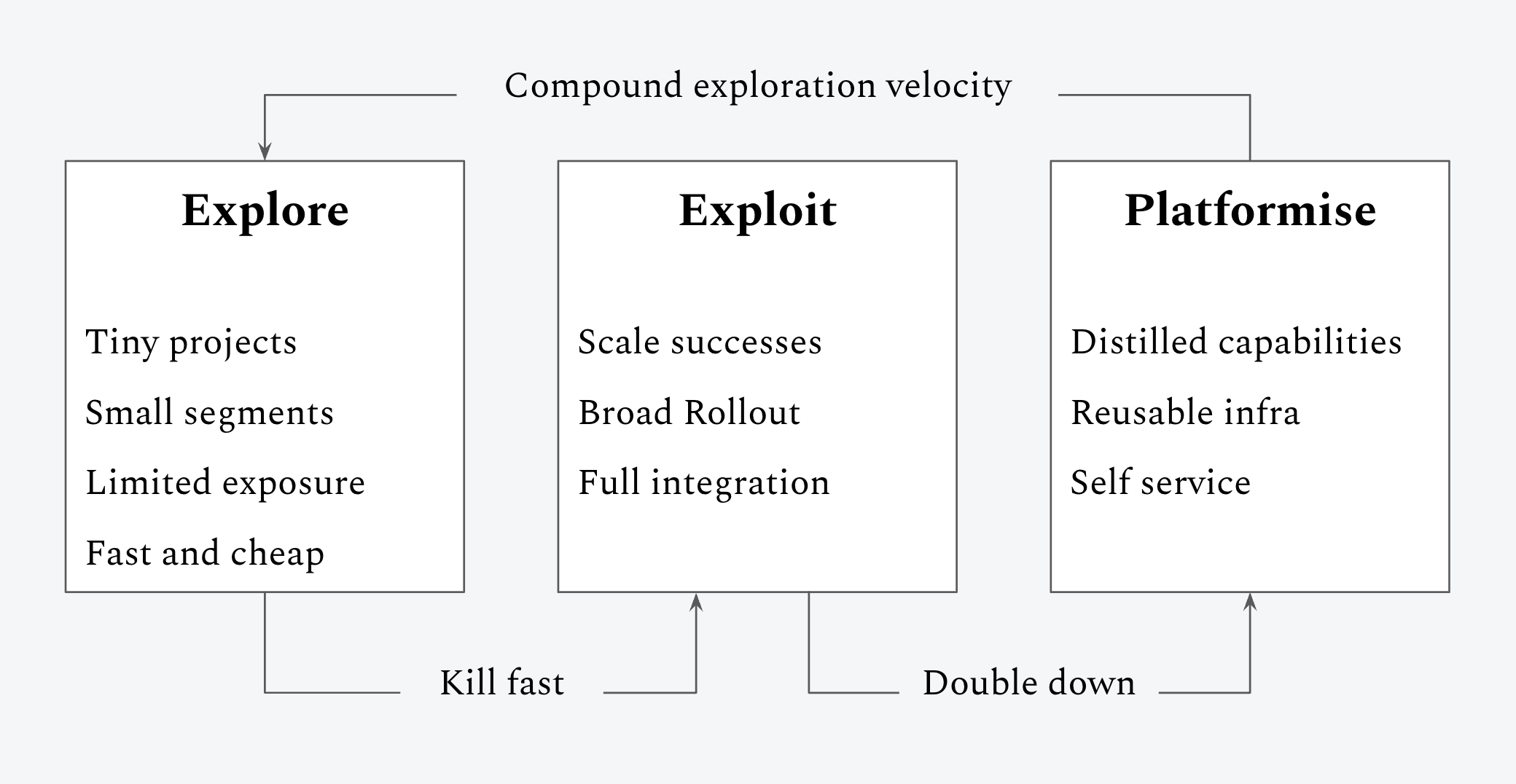
This is also how you prepare for the future you can’t predict. When agents arrived, teams that had been exploring weekly had the muscle to spin up an experiment in days. Teams that had put everything into Exploit were six months behind before they started. And the teams that had platformised their AI capabilities could plug new paradigms into existing infrastructure instead of building from scratch. The framework doesn’t predict the future, but it makes you fast enough that you don’t need to.
A concrete example
Take AI-powered support deflection. This is a classic use case because it touches real cost, has fast feedback loops, and fails loudly when it doesn’t work. Perfect for disciplined AI investment.
Explore
You don’t start by “reimagining support.” You start by isolating one narrow problem.
Pick a single issue category, say, password resets or order confirmation questions. These are high-volume, low-risk, and well understood by agents. You deploy an LLM in a constrained way: either drafting responses for agents or deflecting tickets to self service. No full automation, no broad rollout.
You cap exposure at ~5% of traffic. You run it for two weeks. What you measure is boring and explicit:
Resolution rate vs baseline
CSAT delta
Cost per ticket
Agent intervention rate
Escalation frequency
You’re not trying to prove AI is “the future of support.” You’re asking a much simpler question: is there a dollar here worth chasing?
Most experiments die at this stage. Maybe the model hallucinates edge cases. Maybe CSAT drops. Maybe agents hate it. That’s fine. You’ve spent weeks, not quarters, and thousands, not millions. If there’s no clear signal, you stop.
Exploit
Now assume the signal is real. The experiment shows a 12% reduction in tickets for that category, with no CSAT degradation and lower average handling time. That’s no longer a research question. It’s a business one.
You move into Exploit. You expand coverage to the top 5–10 issue categories that share similar characteristics. You integrate the capability directly into the help flow instead of running it as a sidecar. You invest in guardrails, fallback logic, and operational monitoring. You staff it properly.
And now the bar changes.
This phase has explicit expectations:
Weekly cost savings tracked in dollars
Clear ownership
A defined 60–90 day window to prove the numbers hold at scale
If the deflection rate collapses, or CSAT starts to drift, you don’t debate intent. You stop, surgically fix issues, rerun, or roll back. The project doesn’t get infinite runway just because it once worked in a pilot.
This is the critical shift most teams skip. They treat pilots as proof of inevitability rather than proof of value.
If Exploit works, this becomes one of the few AI projects that actually funds others.
Platformise
Only now does platform thinking start to make sense. You still don’t build a platform off a single use case. You look for reuse pressure.
Your support deflection product succeeds. Separately, a sales assist product shows promise. A fraud triage model is running into similar confidence and fallback questions. A content moderation workflow needs quality thresholds.
Now you have three or four production AI systems asking the same questions:
How do we measure quality consistently?
How do we compare model versions safely?
How do we incorporate human feedback?
How do we decide when automation is allowed vs deferred?
Only at that point do you invest in shared evaluation tooling: common metrics, logging standards, review workflows, offline test harnesses. Not because “AI needs a platform,” but because multiple profitable systems are being slowed down by the lack of one.
Platformisation exists to compress future Explore cycles, not to justify past ones.
The result is compounding speed. The next support experiment launches in days instead of weeks. The next workflow doesn’t need to reinvent evaluation logic. This discipline creates leverage.
The Rules
Exploit funds Explore and Platformise. No Exploit performance, no permission to explore or invest long. This is how you answer the question “what are we getting for this?”
Every project has a track. Untracked AI work doesn’t get funded. If someone can’t tell you whether their project is Explore, Exploit, or Platformise, they haven’t thought hard enough.
Track migrations are explicit decisions, not drift. Projects get promoted, killed, or demoted, never “let’s give it one more quarter.” That sentence has killed more AI projects than bad data ever has.
The 20/50/30 is representative, not a target. Unspent exploration budget is a feature, not a failure. And the ratios flex by stage. A seed-stage startup might be 80% Exploit, 20% Explore, 0% Platformise, and that’s exactly right. An enterprise with $80 million in ARR might run the full 20/50/30. The principle is constant, but the allocation can adapt.
Rebalance quarterly. Review the full portfolio. Which Explore experiments found signal? Which Exploit projects hit their 90-day milestones? Which Platformise investments are actually compounding velocity? Move budget toward what’s working. Kill what’s not. This is the portfolio discipline you already apply to every other investment. Apply it here.
The Transition
If you’re reading this and thinking “we already have AI projects running with no tracks, no milestones, and no kill criteria”, you’re not alone. That’s the default state of most organizations right now.
You can’t walk in Monday and announce that everything is changing. Here’s the move instead.
Start with an audit. Map every active AI initiative. For each one, answer three questions: what’s the dollar it’s chasing? What’s the milestone for this quarter? What happens if it misses? If no one can answer those questions for a given project, that project goes on a 30-day clock. Define the answers or kill it.
If you’re running a portfolio of AI initiatives, this is the political cover you’ve been missing. You’re not killing someone’s pet project, you’re applying the same milestone discipline you apply to every other investment. Frame it that way. “We’re not cutting AI. We’re making AI accountable.” The zombie projects die. The budget they were consuming flows to the projects that are actually working. Your best teams get more resources, not less.
If you’re about to pitch the next AI feature, this is your competitive advantage. Don’t walk into the room with “we should build an AI feature.” Walk in with “This is an Exploit-track project. Here’s the funnel. Here’s the dollar. Here’s the 90-day milestone. Here’s what we kill if it misses.” That pitch gets funded every time.
If you’re watching funded competitors burn cash on AI features with no revenue model, keep going. Your ROI obsession is correct. The discipline you’re forced into by your runway is the same discipline that separates the 6% from the 94%. You’re not the small one. You’re the smart one.
Every AI project should have a dollar sign attached. Every one.
Not because innovation doesn’t matter. It does. But because the projects that change the world are the ones that survive long enough to do it. And survival requires proof. IBM Watson had a $5 billion budget. It didn’t survive. Zillow Offers had the largest real estate dataset in America. It didn’t survive. The projects that survive are the ones that can answer the question: what did we get for that?
The accountability gap is closing. The era where “we’re investing in AI” was enough to satisfy boards, impress LPs, and justify headcount is ending. The firms that imposed discipline early, that tracked ROI from day one, that killed projects at 90 days, that required every initiative to name its dollar before writing a line of code, will outperform.
The firms that let “strategic” be a hiding place will write checks they can’t explain. Some already are.
You already know how to run disciplined investments. You already know how to set milestones and kill what doesn’t work. You already know that “strategic” without a number is just another word for “we don’t know.”
Apply what you know. AI doesn’t get special treatment.
ROI or die.
Claim Verifications and Citations