

The Product Builder's Guide to Machine Learning — Part 1 of 3
Great Machine Learning models don’t always become great Products, not because of the ML itself, but because of the Design and the…

If you haven’t already, consider subscribing to FoundIt for more product building content!
Share the ML guide with friends or colleagues who might find it useful!
Building your first Machine Learning product can be overwhelming — the sheer amount of moving parts, and the number of things that need to work together can be challenging. I’ve often seen great Machine Learning models fail to become great Products, not because of the ML itself, but because of the supporting product environment. UX, Processes, and Data, all contribute to the success of a Machine Learning model.
Over the years of building Machine Learning products, I’ve come up with a framework that usually works for me. I break down a Machine Learning product into eight steps. Here they are at a glance:
Identify the problem
There are no alternatives to good old fashioned user researchGet the right data set
Machine learning needs data — lots of it!Fake it first
Building a Machine Learning model is expensive. Try to get success signals early on.Weigh the cost of getting it wrong
A wrong prediction can have consequences ranging from mild annoyance to the user to losing a customer forever.Build a safety net
Think about mitigating catastrophes — what happens if Machine Learning gives a wrong prediction?Build a feedback loop
This helps to gauge customer satisfaction and generates data for improving your machine learning modelMonitor
For errors, technical glitches and prediction accuracyGet creative!
ML is a creative process, and Product Managers can add value
For the sake of my sanity and for better readability, I’ll split this post into three parts. This part covers steps 1 through 3. Here goes step 1!
1. Identify the Problem
Machine Learning is a powerful tool for solving customer problems, but it does not tell you what problems to solve. Before even beginning to decide on whether Machine Learning is the right approach, it is important to define the problem.
Invest in user research
There are no shortcuts to good old fashioned user research. Every successful product identifies a specific user need and solves for it. Conduct a thorough user research in order to identify the pain points of the user and prioritize them according to user needs. This helps to build a user journey map, identifying critical flows and potential roadblocks. Further, the roadmap is super useful for defining processes and flows that need to be modified for your ML solution to work in the first place. Here is a summary of what good user research should accomplish.
Once the problem is identified, we need to explore if machine learning offers the best solution.
Look for one of these characteristics in your problem:
Customization or personalization problem — one size does not fit all
Problems where users with unique characteristics need to be identified are usually great candidates for machine learning.

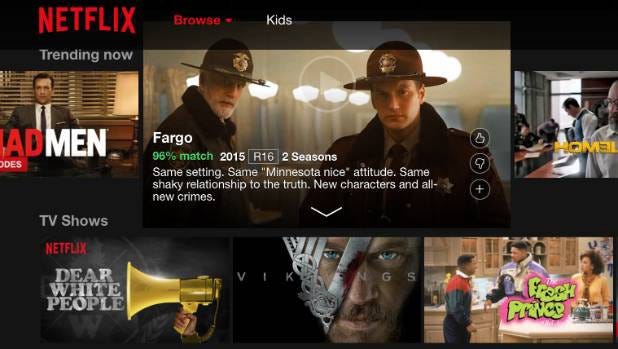
Personalization or customization problems look to identify specific users and cohorts that may be interested in specific content. They are usually driven by past user actions, user demographics, etc.
Repeatable sequence of steps
Processes which require a repetition of the same sequence of steps once the problem is identified are usually great candidates for automation. For example, the entire ‘cancel your order’ flow in e-commerce can be automated if the intent of automation is identified. Further, recommendations for next steps can also be made based on a user’s last action.Recognizes or matches pattern
Look for repeated patterns that you can learn from. Spam engines, for example, index characteristics of spam messages (including text, subject line, sender information, etc.) and look at how many users marked a similar message as spam in order to to identify a potentially spam email.
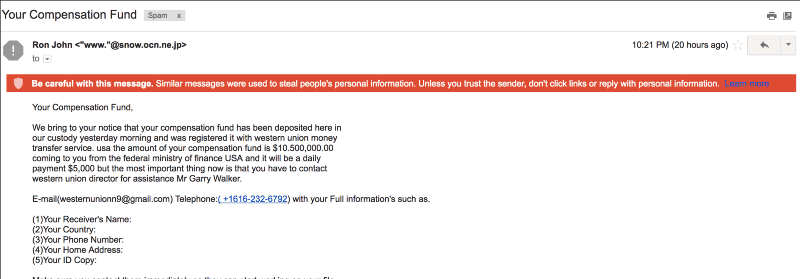
Uber’s approach to customer service relies on identifying the best solution for a specific problem based on previous actions of customer service agents.

2. Get the right data set
The success or failure of machine learning relies on the coverage and quality of your data set. A good data set has two characteristics — a comprehensive feature list, and an accurate label.

Features are the input variables to your model. For example, while building a recommendation system, you may want to look at a user’s purchase history, the closest matches for the products they bought, their buying frequency, and so on. Having a comprehensive feature list ensures that the ML model understands enough about the user in order to make a decision.
Labels tell the model the right from the wrong. A machine learning model is trained iteratively on a data set. In each iteration, the model makes a prediction, checks if the prediction is right, and calibrates itself for wrong predictions. It is thus important for the model to know whether or not a prediction is right. Labels convey this information to the model. For a recommender system, this label will be whether the recommended item was indeed purchased. Having the right set of labels influences the model’s performance.
Bonus: Some awesome resources to get you started into what labelled data looks like:
* Kaggle datasets : Huge collection of labelled data on just about anything!
* Quickdraw: Crowdsourced data on line images and strokes
3. Fake it First
Investing in machine learning models is expensive. Building a dataset with the right features and labels, training the model and putting it in production can range from a few weeks to a few months. It is important to get a signal early on and validate if the model will work. A good idea is to fake the interaction first, for a small set of users.
For personalization, have a list of items ready for a user to select, based on what they selected last. Simple rule-based engines are often the first steps to evolution into a more complex machine learning model. Some examples of rule-based recommenders:
If the user bought pasta, they probably need cheese too
A user buys toothpaste once a month, so we recommend it to them a month after their last purchase
A user always pays by credit card, so we surface that as the default payment option next time
It’s obvious that we cannot write simple rules to cover every case — and that is when the power of machine learning can be used best — but a few simple rule based proxies go a long way into validating the outcome of the machine learning approach.
For automating customer flows, it may be a good idea to ask a human on the other side to do exactly what an automation would do — and nothing else. Companies often test if they should build chatbot through a controlled release with a human answering questions on the other side.
The idea is to test if users respond positively to machine learning. While these techniques might not give the best results, they are important for getting a signal. Getting a signal early on can save time and effort, and help correct the vision and direction of the product. This is your best shot at guaranteeing returns on the investment put into building a Machine Learning system.
If you haven’t already, consider subscribing to FoundIt for more product building content!
Share the ML guide with friends or colleagues who might find it useful!